Data Input/Output
Input
Click Slect object, and then select a sample set.
- Data list of the sample set under Output data.
- Statistical analysis of the sample set fields, including attribute, type, number of missing values, maximum, minimum and more.
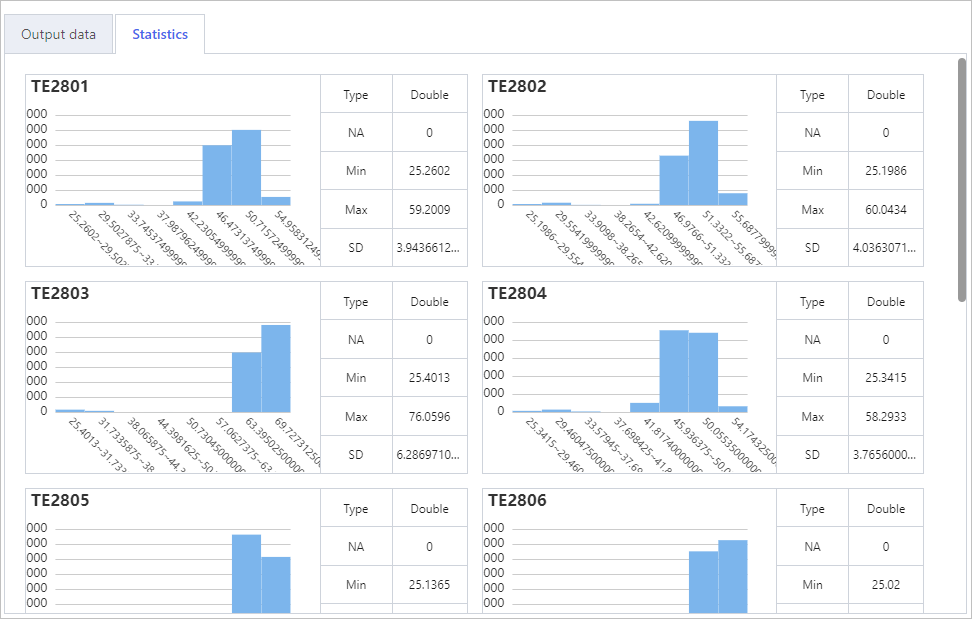
Output
Data Preprocessing
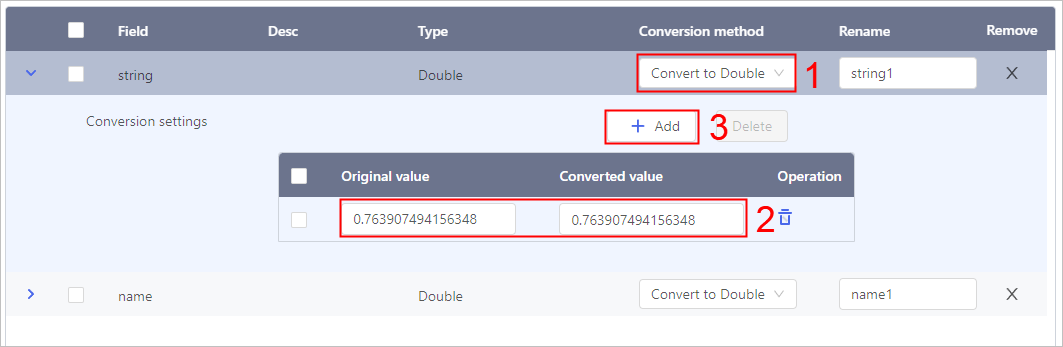
Char Conversion
- Click Select object, and then select fields to convert.
- Select a conversion type.
- Set the conversion rules.
Data Balancing
Select an enumeration field, and then select a balancing algorithm and set its related parameters.
| Parameter | Description |
|---|---|
| Balancing method | Select a balancing algorithm.
|
| Sampling method | Select a method to set the oversampling or undersampling field.
|
| K-Nearest Neighbors | Set the number of KNN for algorithms to calculate. |
| Random seed | Enable it to fix the amplitude/reduction value for repeated debugging. |

Used SMOTE to oversmaple the Non-minimum category.
Data Copy
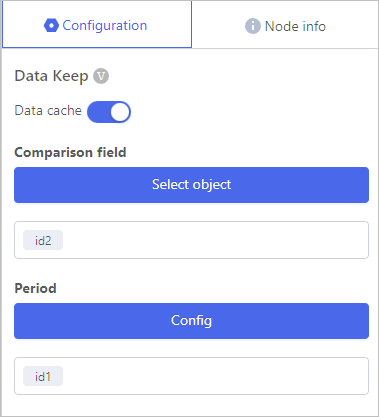
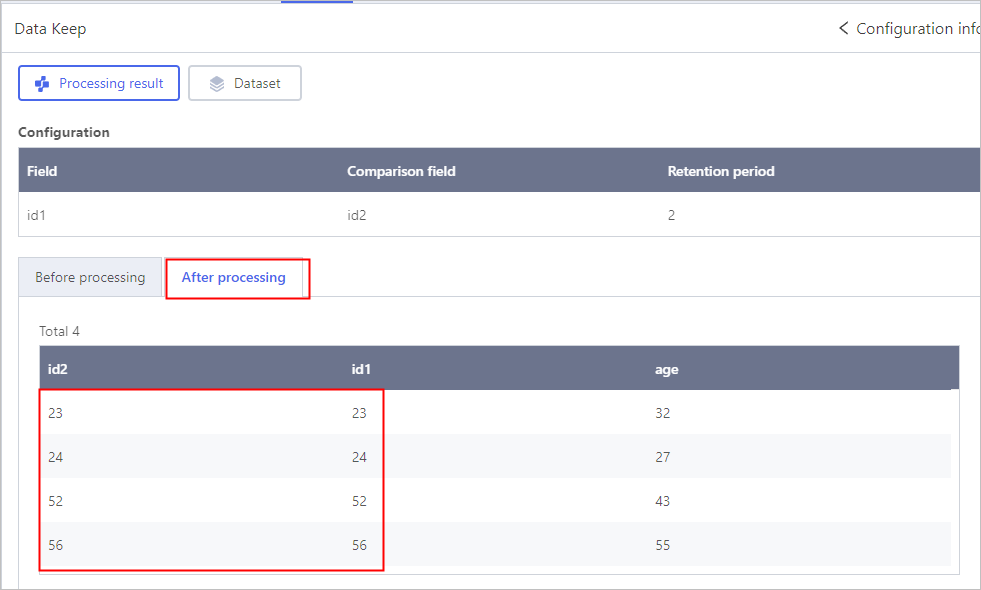
Data Keep
- Enable Data cache.
- Click Select object, and then select comparison fields.
- Click Config, and then select fields to be kept with the Comparison field.
ONly numerical fields are available.

Data Merge
Enable Auto handle duplicate field names, and duplicate field name will add a suffix 1.
Under Node info, view the input and output data structure.
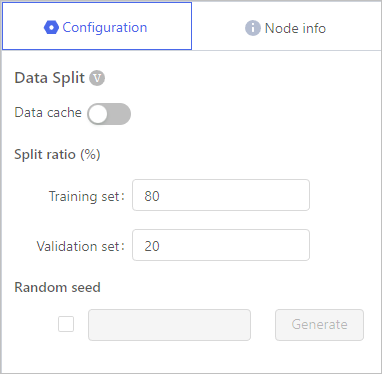
Data Split
Split the original data set into Training set and Validation set. Used for regression or classifier algorithms.
- Set the ratio between trainning set and validation set, and during each debugging, the actual ratio will be slightly different from the set value.
- Select whether to enable Random seed.
- Enable Random seed, repeat debugging the experiment and the same ratio as the last time will be used again.
- Disable Random seed, repeat debugging the experiment and the ratio will be slightly different each time.
For example, the ratio is set to 80/20.
- Enable Random seed, the ratio of the first debugging may be 80.21%/19.79%, and the second debugging ratio will still be 80.21%/19.79%.
- Disable Random seed, the ratio of the first debugging may be 80.21%/19.79%, and the second debugging ratio may be 79.91%/20.09%.
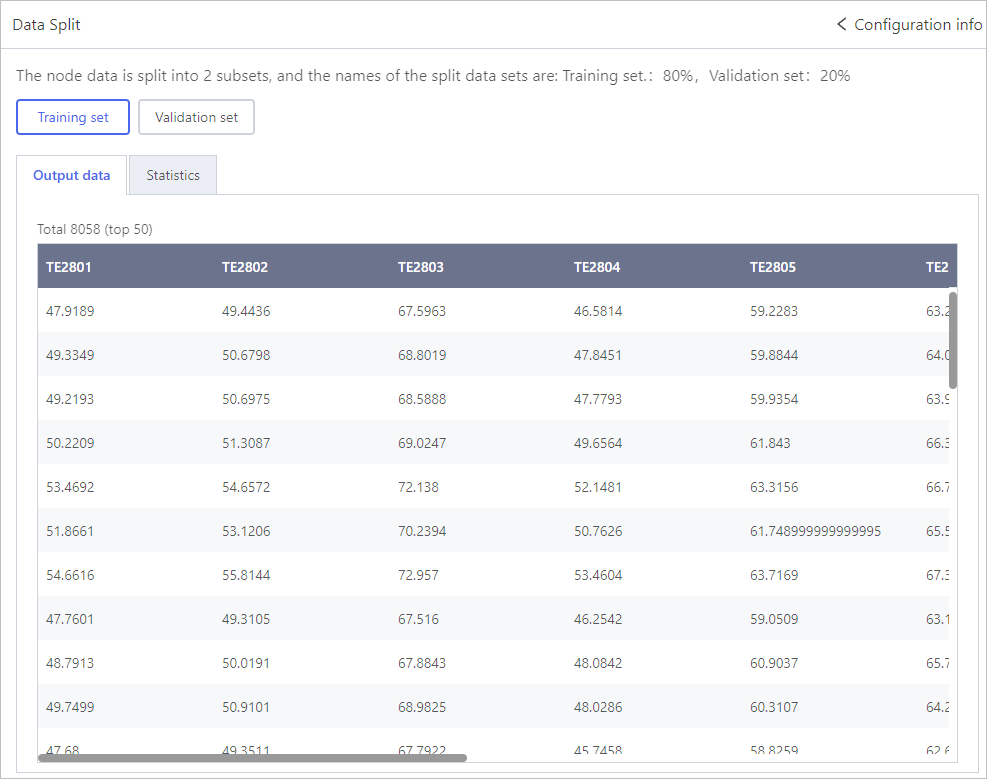
Displays the data of each set. Only the first 50 entries are displayed.
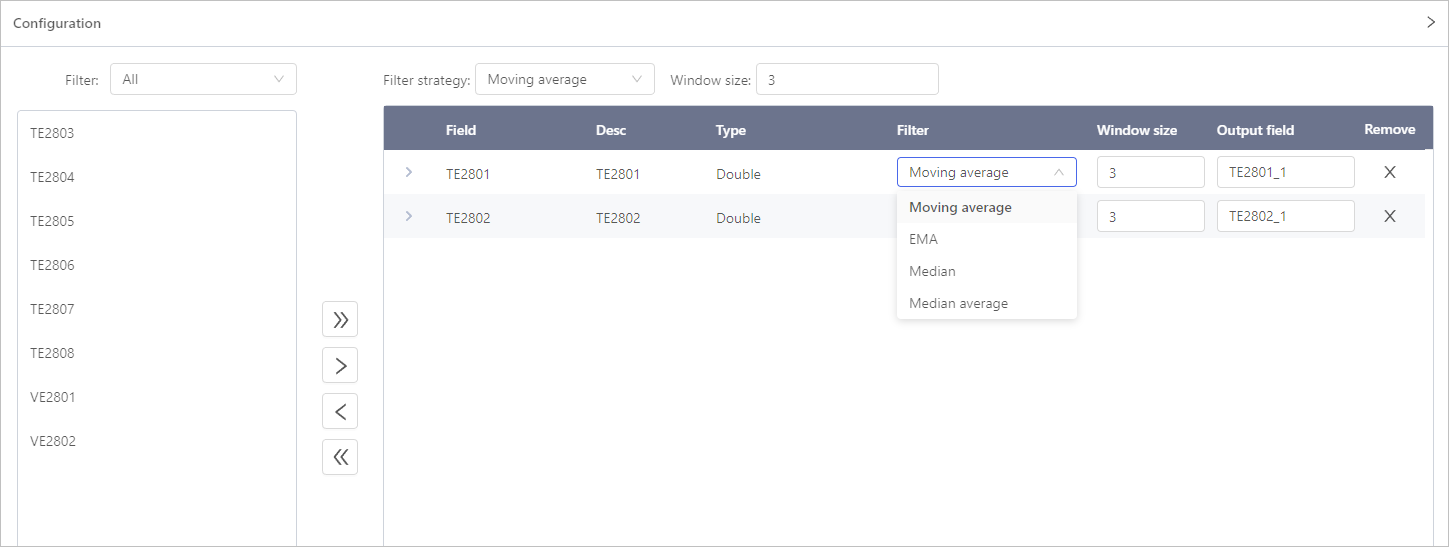
Data Filter
- Select fields for filtering.
- Select a filter and set the filter window size.info
When selecting EMA, you can either use adaptive weight or manually set the weight. For manual set, keep 2 decimal places.
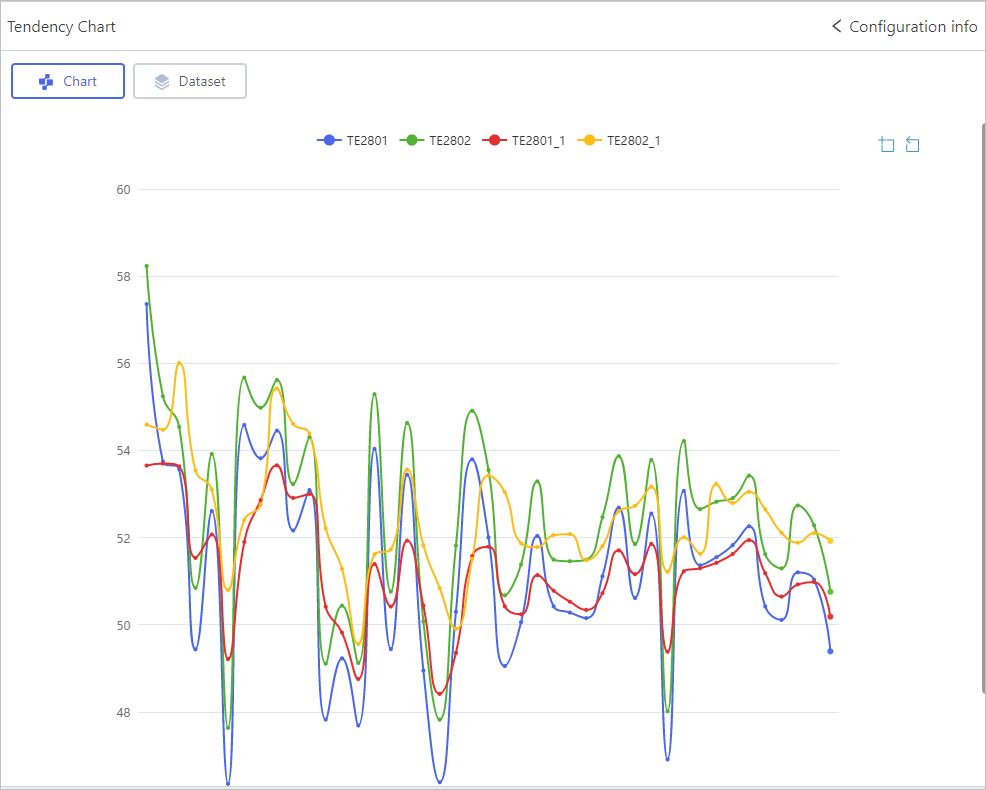
View the effect with the Tendency chart element.
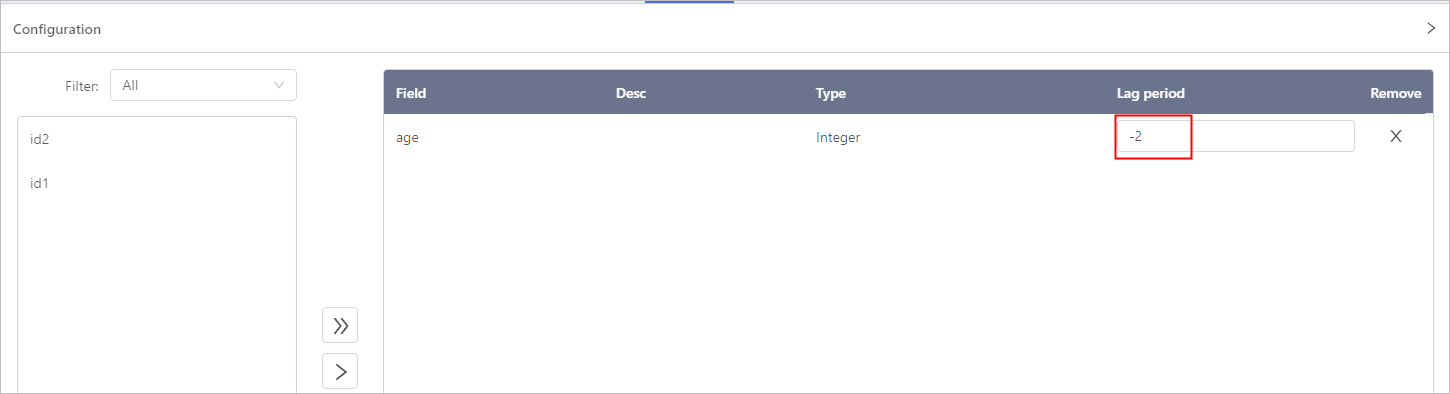
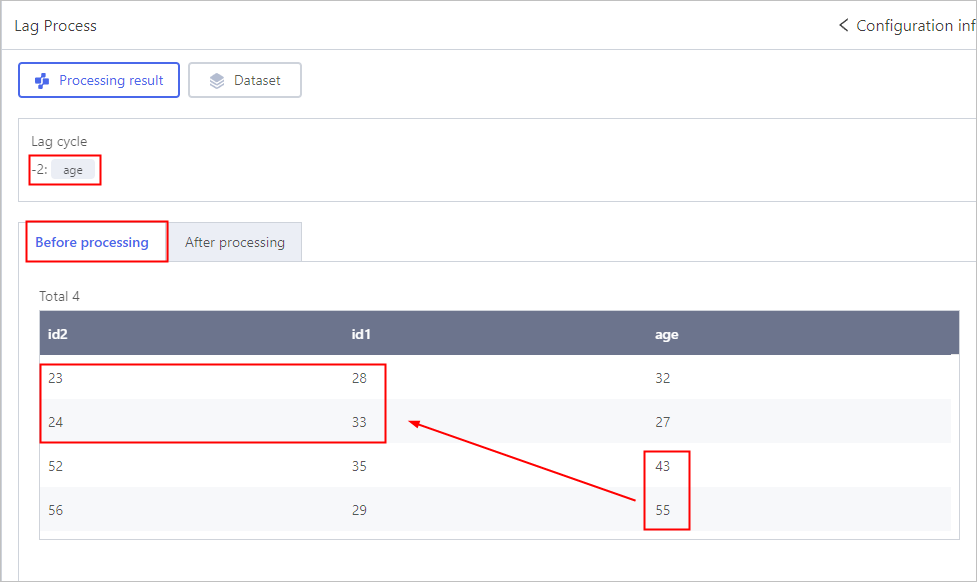
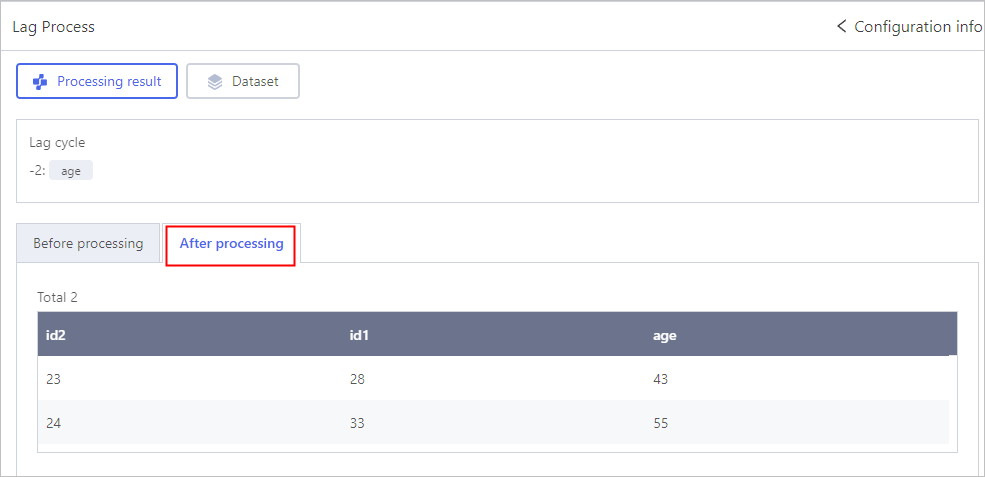
Lag Process
Click Config, and then select the feature field and set the lag cycle.
- Set lag cycle to a positive integer, the feature field is in advance.
- Set lag cycle to a negative integer, the feature field is left behind.
- Set lag cycle to 0, the feature field is at the same pace as other fields.
The lag cycle cannot be larger than the number of data rows.
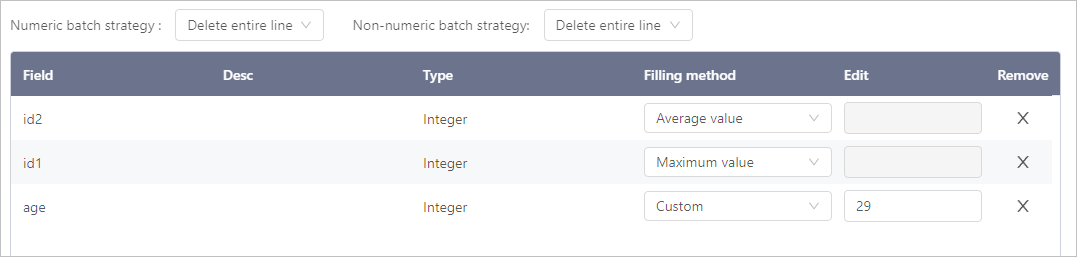
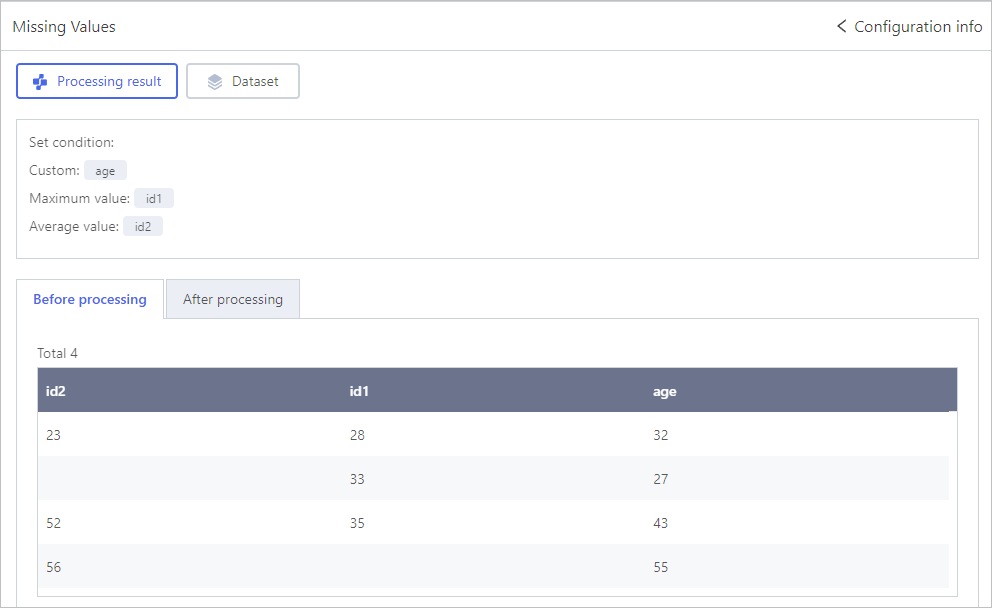
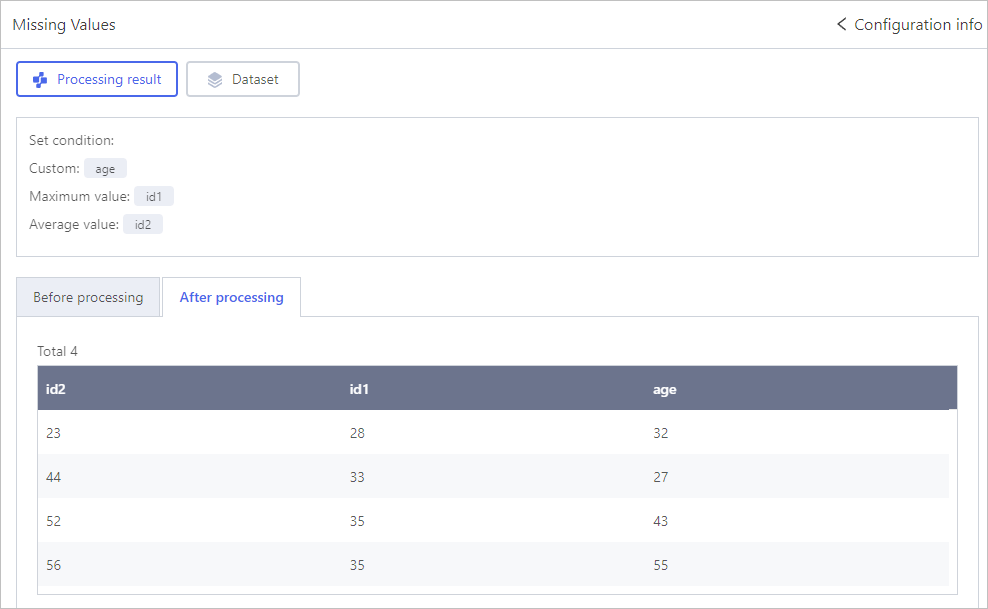
Missing Values
Click Select object, select fields that have missing values and set the processing methods.
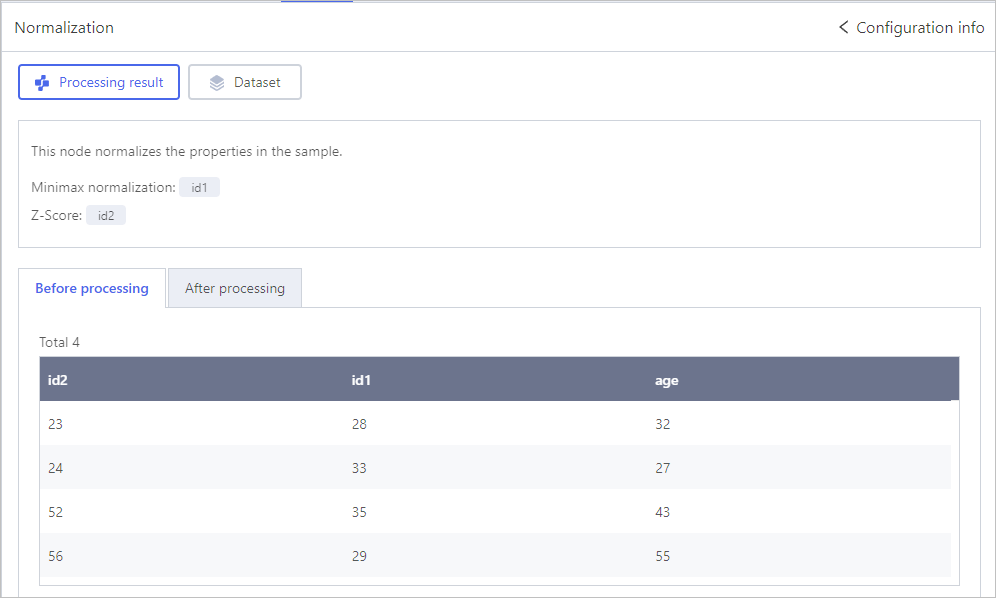
Normalization
Click Select object, select fields that needs to be normalized and set the processing methods.


Num Conversion
Click Select object, select fields that needs to be converted.
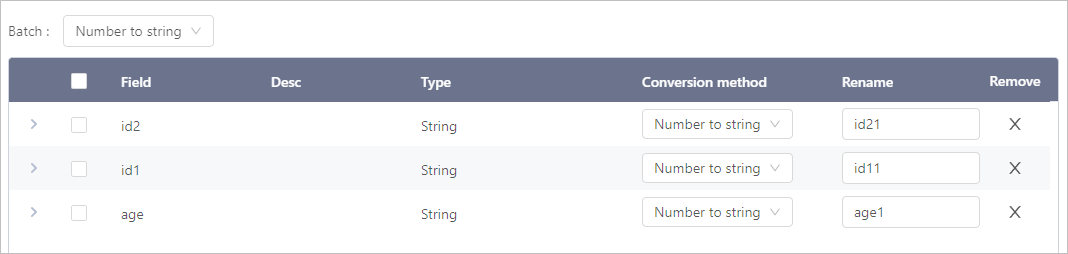
Same values with string as data type.
Set Role
Click Select object, select fields and set them to independent and dependent variables.


Step Limit
Click Select object, select fields and set them to independent and dependent variables.

| Parameter | Description |
|---|---|
| Comparison field | Select fields to be the compared objects. |
| Step deadband | Buffer value between the difference of values of comparison field and original field, and the step limit value. |
| Step limit | Limit of the difference between values of comparison field and original field. The value must be larger than the step deadband. |
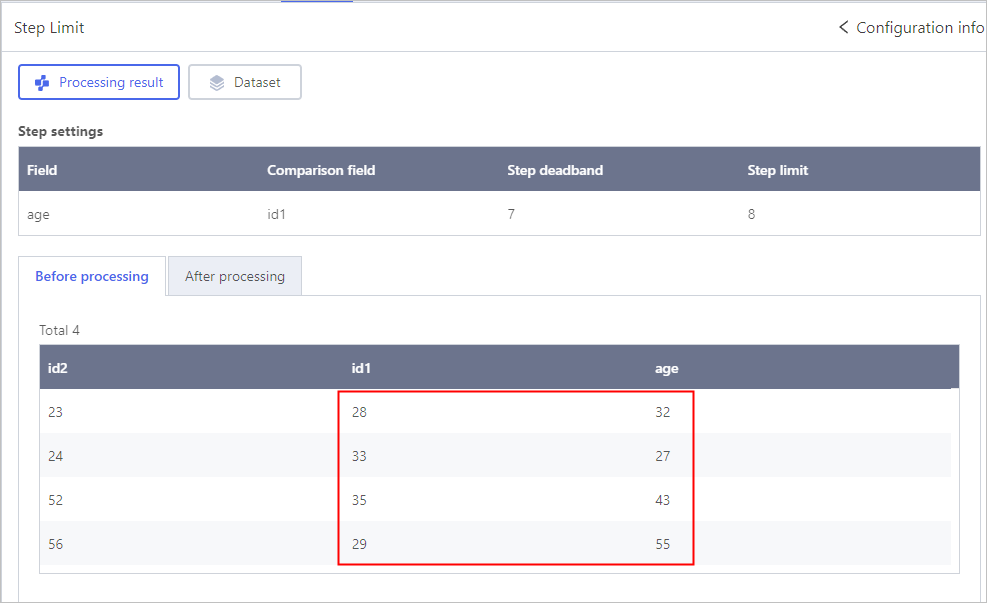
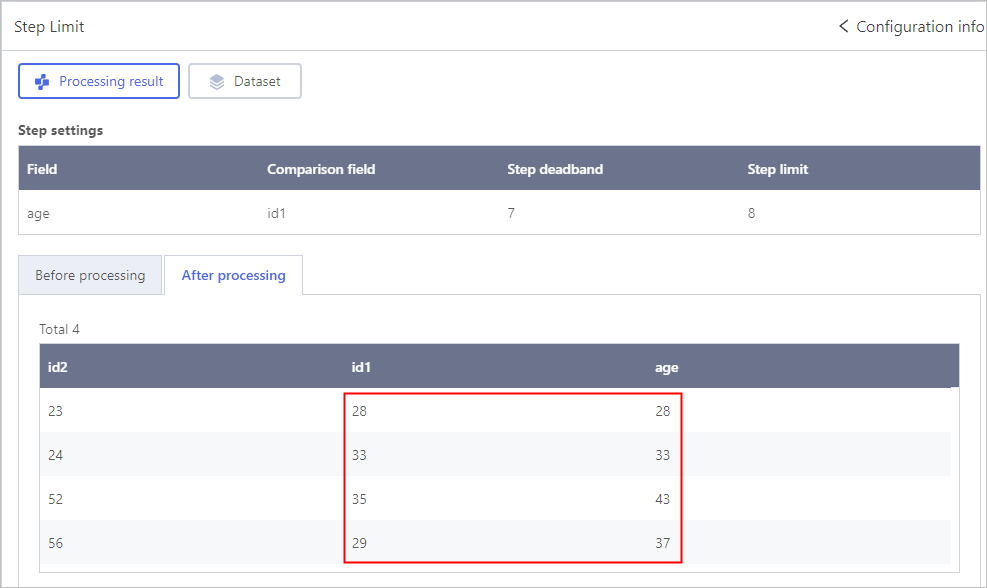
An example to demonstrate the relation betweend step deadband and limit.
- The orginal field value is 10, comparison field value is 3, step limit is 3, step deadband is 1. After processing, the original field will be 6 (3 + 3), beacuse the difference 7 > 3.
- The orginal field value is 10, comparison field value is 3, step limit is 10, step deadband is 8. After processing, the original field will be 3, beacuse the difference 7 < 8.
- The orginal field value is 10, comparison field value is 3, step limit is 8, step deadband is 5. After processing, the original field will be 10, beacuse the difference 5 < 7 < 8.
Signal Processing
Digital Filter
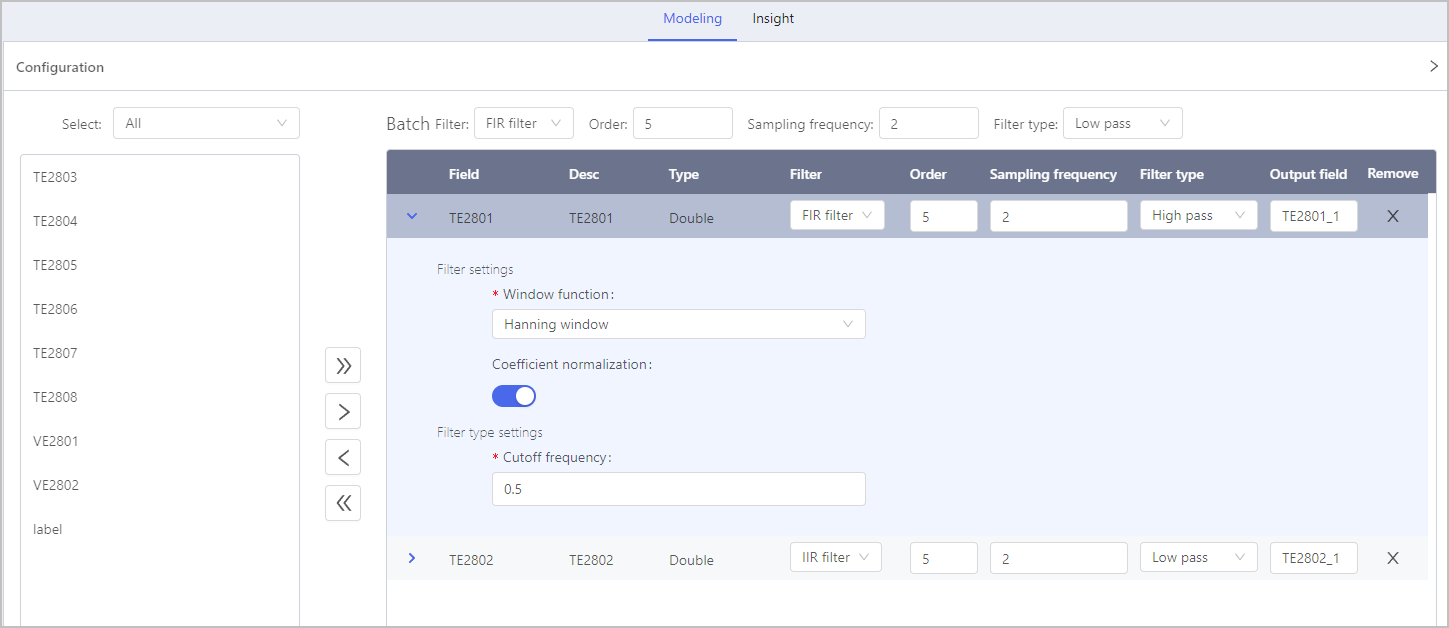
Click Select object, select fields and set the filter, frequency and type.
| Parameter | Description |
|---|---|
| Batch Filter | Select filters from FIR filter and IIR filter. |
| Order | The higher the order, the more complicated and accurate the frequency response of the filter is. |
| Sampling frequency | The number of signal sampling every second. |
| Filter type |
|
| Window function | Adjust and restrict the frequency response of the filter. info Only available for FIR filter. |
| Coefficient normalization | Zoom the filter coefficient to a specified range to assure the filter steadiness. info Only available for FIR filter. |
| Cutoff frequency | The frequency where the filter stops passing signals. |
| Standard deviation | Controls the window function shape and spectral characteristics. The larger the number, the wider the Guassian window. |
| Maximum ripple | The maximum amplitude of Chebyshev I filter within the band-pass frequency range. info Unavailable for Butterworth filter. |
| Minimum attenuation | The minimum attenuation of Chebyshev I filter within the band-stop frequency range. info Unavailable for Butterworth filter. |
Wavelet Transform
Click Select object, select fields and set the filter parameters.
| Parameter | Description |
|---|---|
| Wavelet filter | Select a wavelet filter to decompose and recompose signals. |
| Decomposition depth | The level of decomposing signals. |
| Boundary processing | The way of processing boundry signals.
|
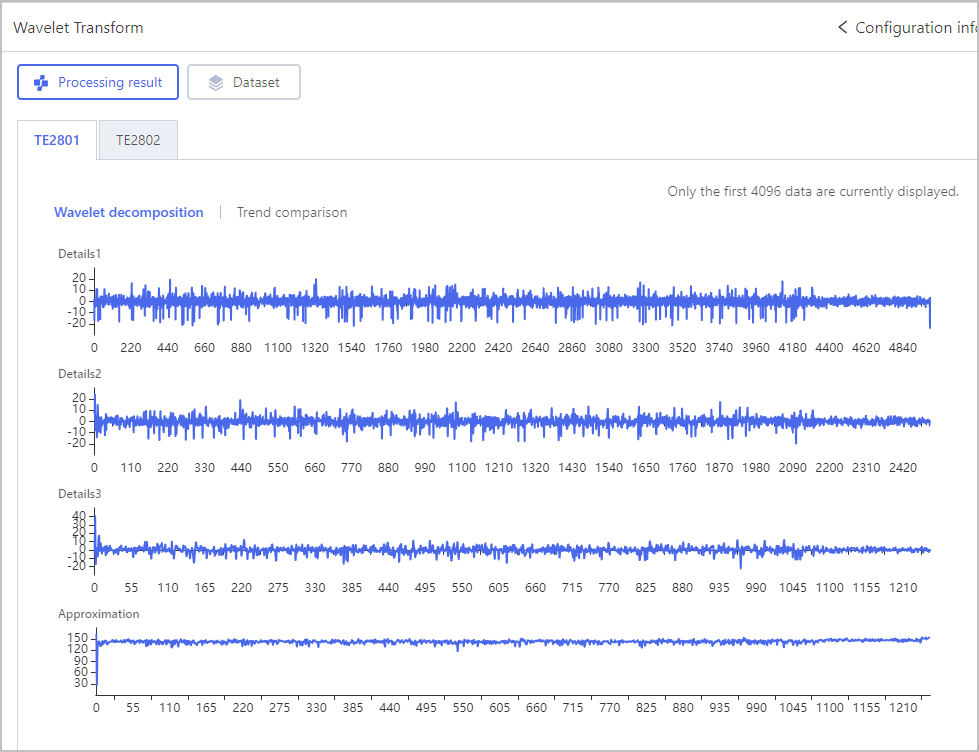
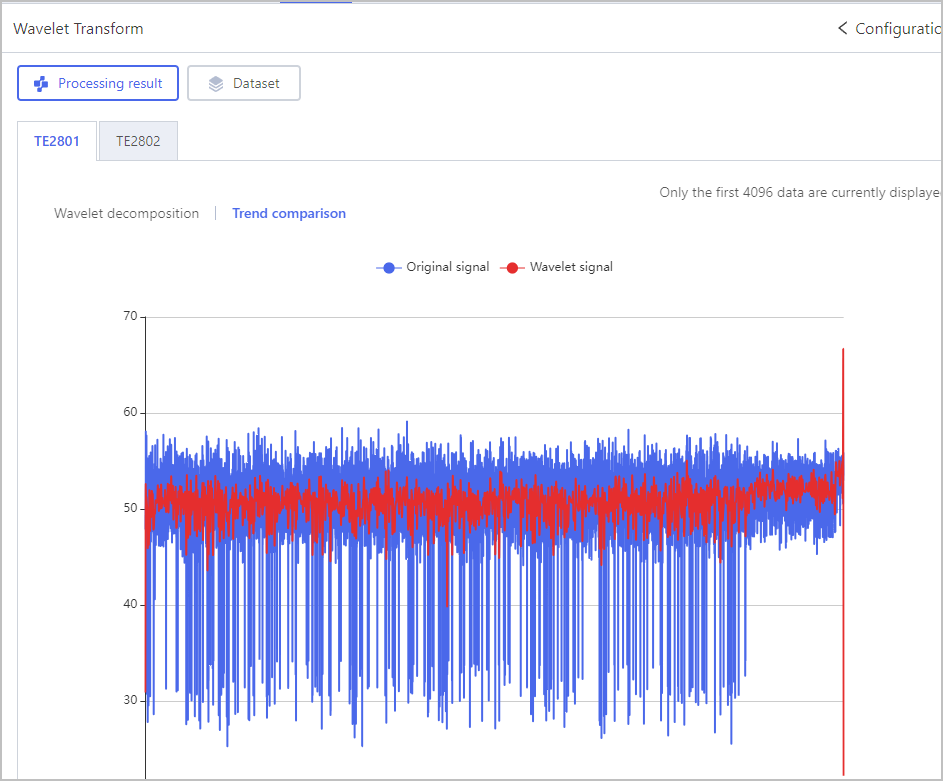
Feature Engineering
Correlation Matrix
Click Select object, select fields and algorithm type.


Feature Expression
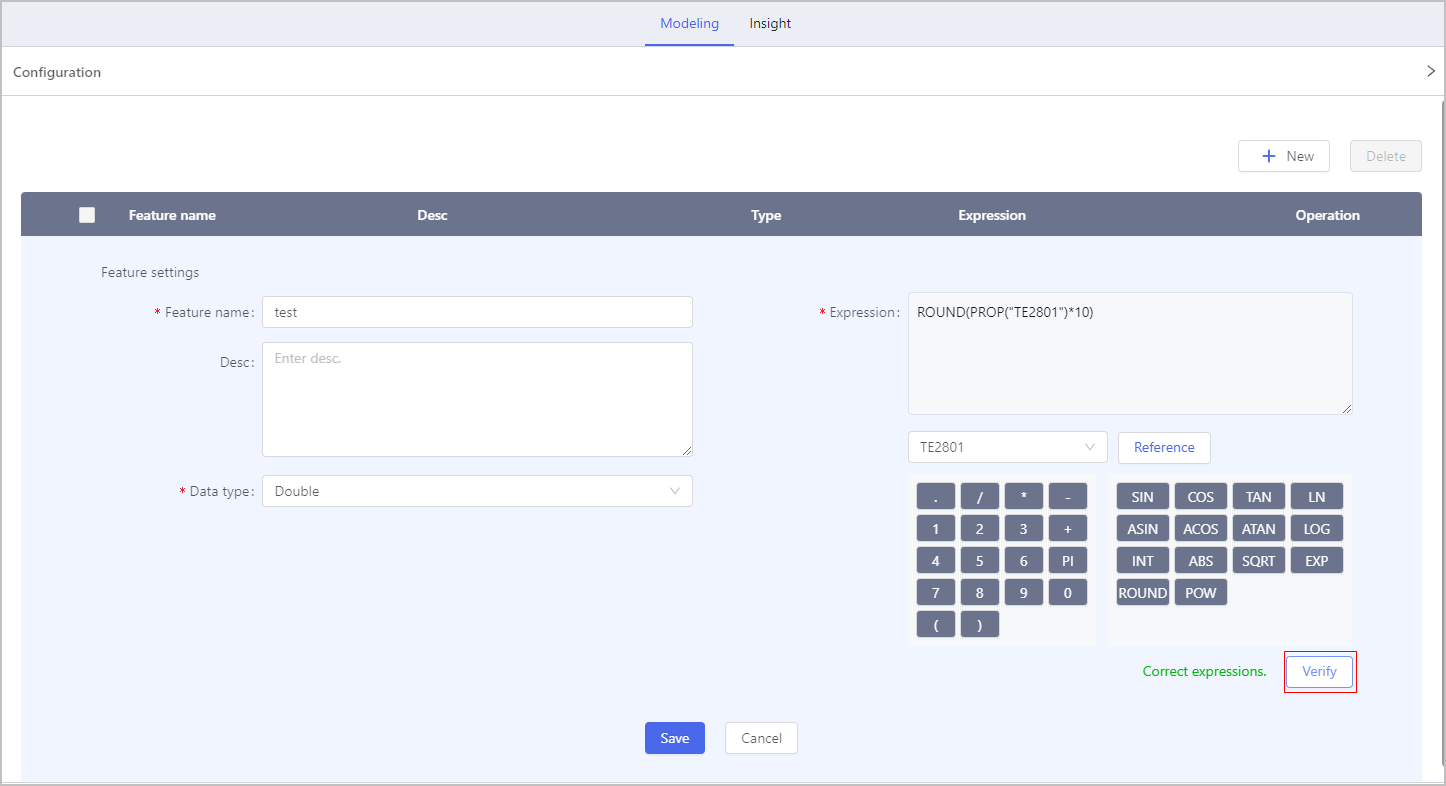
- Click Select object, set feature name and data type.
- Select a field and click Reference.
- Set the expression using the on-screen keyboard.
- Click Verify to check whether the expression is correct.
- Click Save and then click OK.
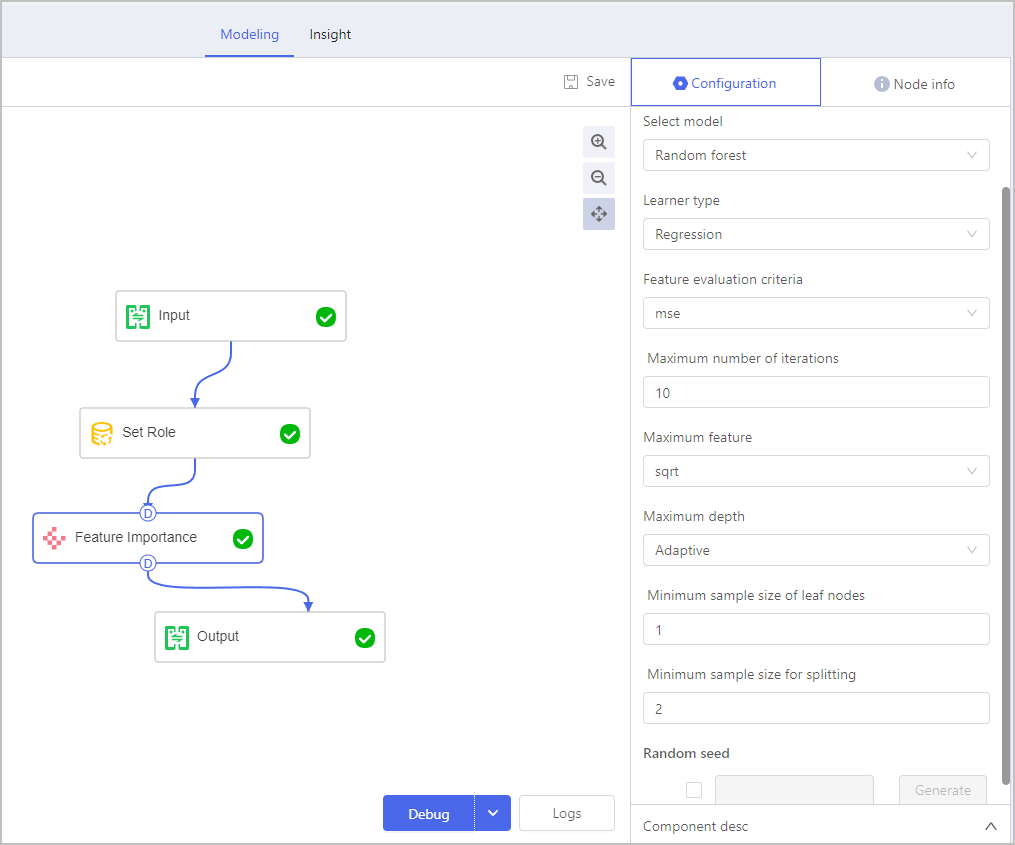
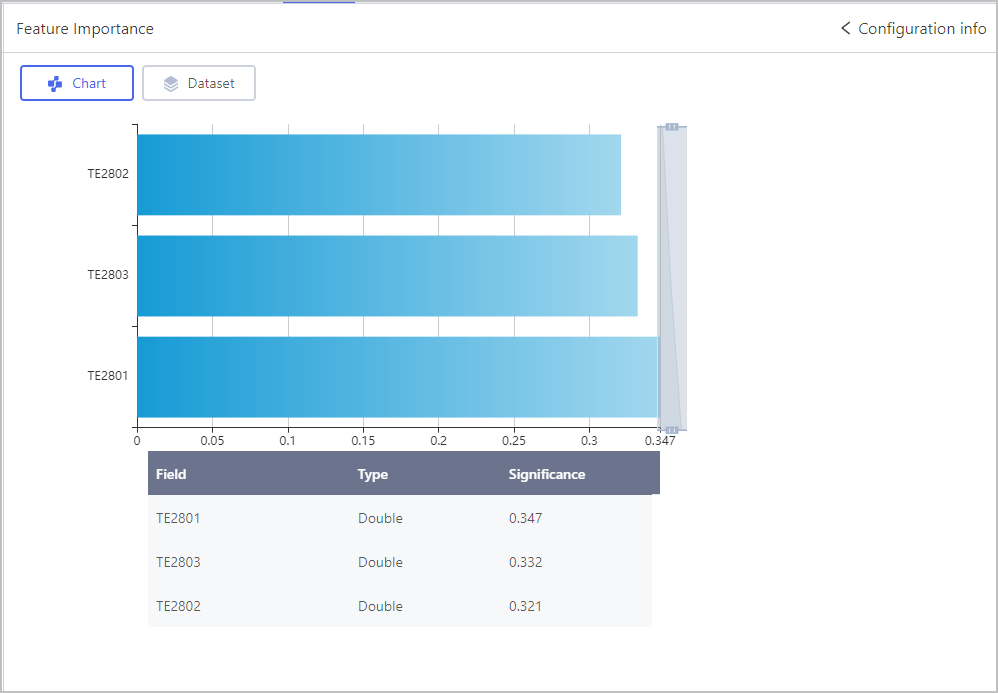
Feature Importance
Provided models are based on decision trees, including random forest and gradient boosting decision trees.
Make sure you add a Set Role component before Feature Importance.
| Parameter | Description |
|---|---|
| Learner type |
|
| Feature evaluation criteria |
|
| Maximum number of iteration | The maximum number of iterations or the maximum number of decision trees in the random forest ensemble. |
| Maximum feature | The maximum number of features considered during the construction of each decision tree in the ensemble. |
| Maximum depth | The limit set on the maximum depth or number of levels of each decision tree in the ensemble. |
| Minimum sample size of leaf nodes | Specifies the minimum number of samples required to consider further splitting a node and form a leaf node. |
| Minimum sample size for splitting | Specifies the minimum number of samples needed to consider splitting a node further. |
| Random seed | Enable it to fix the amplitude/reduction value for repeated debugging. |
| Parameter | Description |
|---|---|
| Step length | Controls the contribution of each decision tree to the overall model. |
| Subsampling | The technique of randomly selecting a subset of training samples during each iteration. |
| Loss function |
|
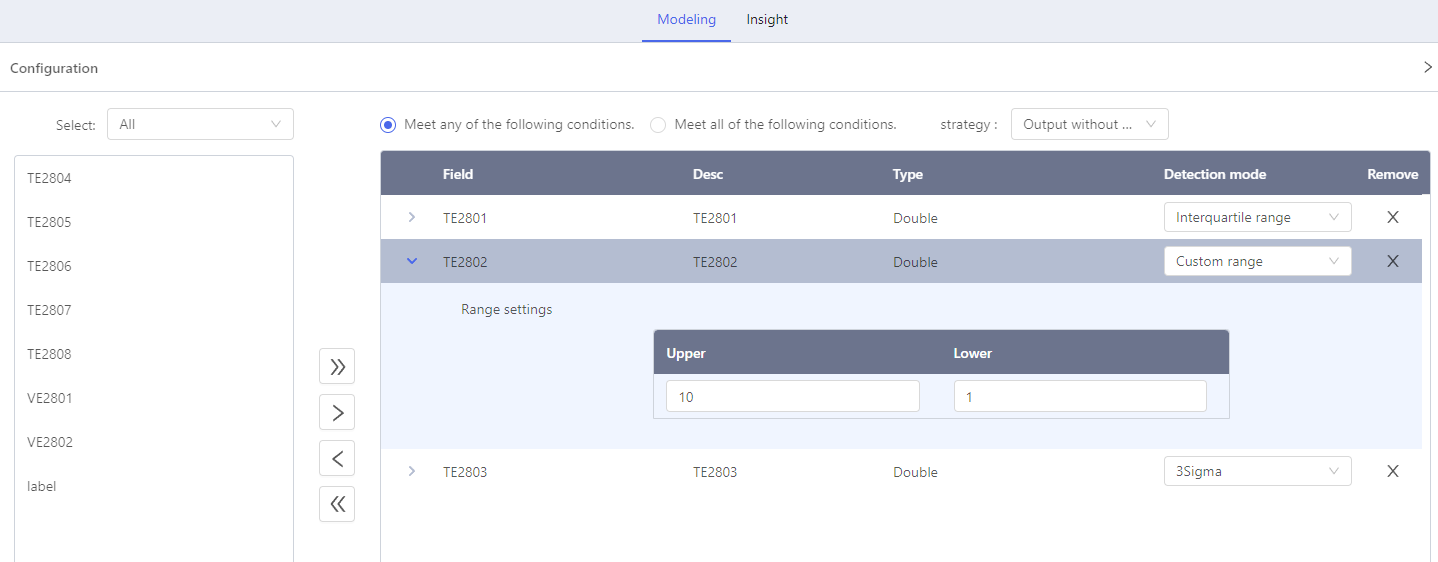
Outlier Detection
Click Select object, select fields and corresponding detection mode.

Principal Component Analysis
Click Select object, select fields and set PCA components.
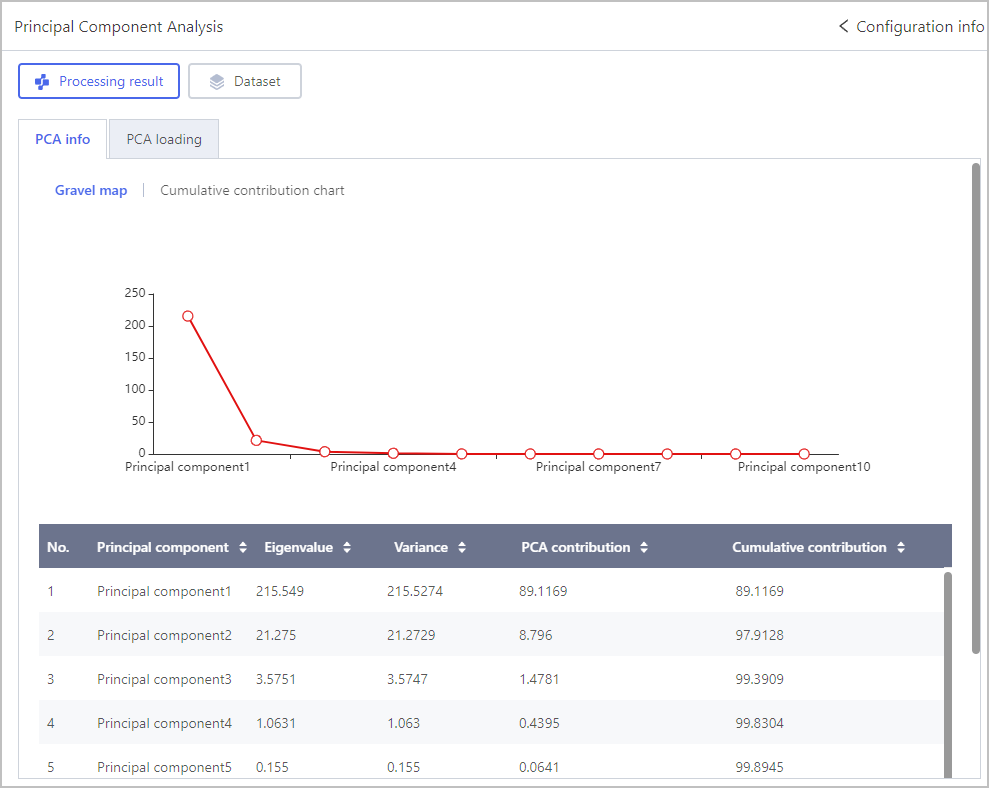
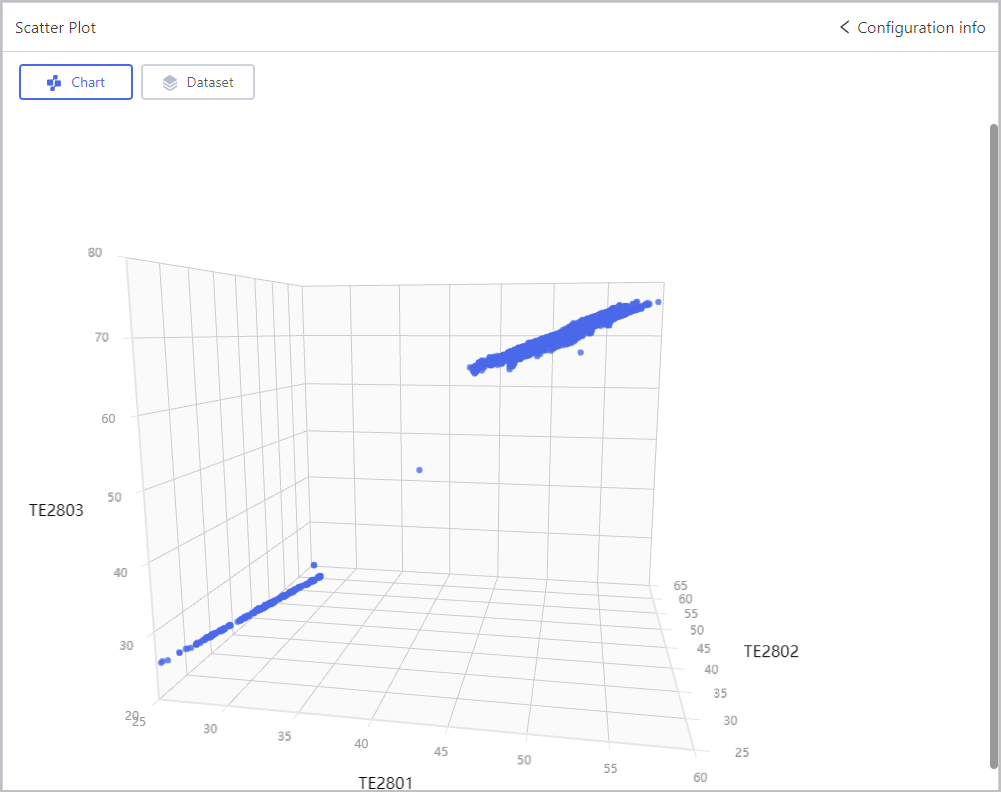
Scatter Plot
Click Select object, select chart type and corresponding fields, and the display color scheme on the coordinate system.
Select Group to group fields, and the group field must be string.
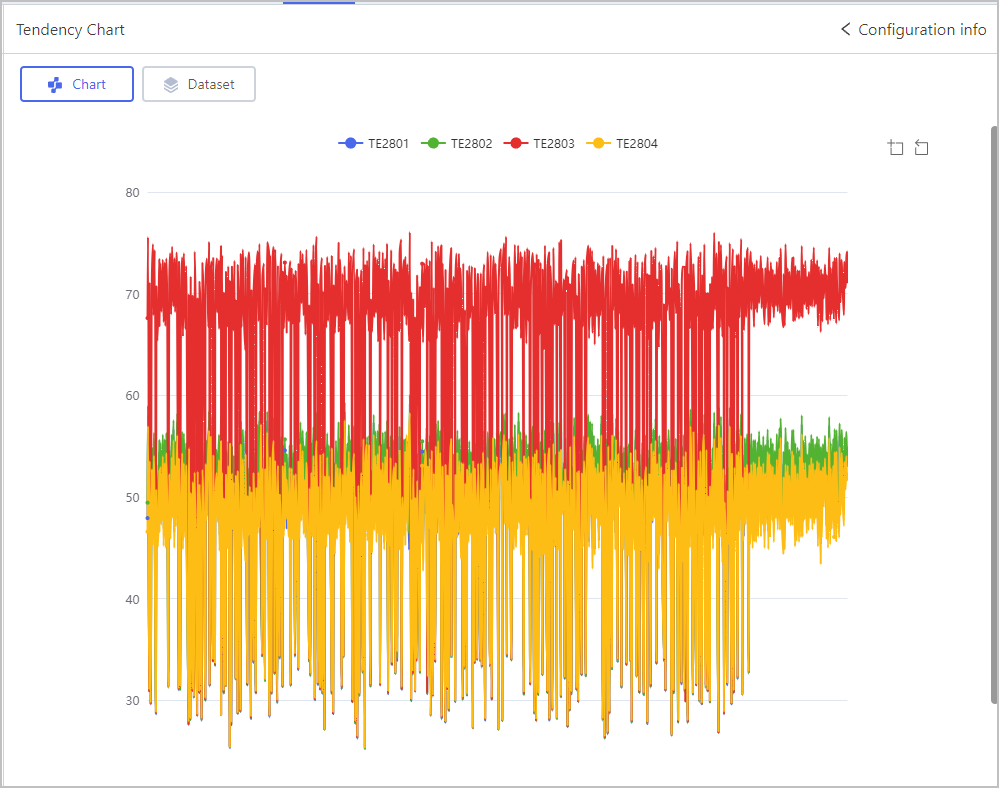
Tendency Chart
Click Select object, select fields and the display color scheme on the tendency chart.
Machine learning
Make sure you add a Set Role component before machine learning operators.
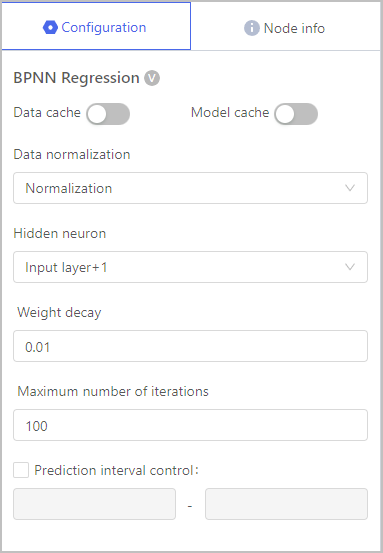
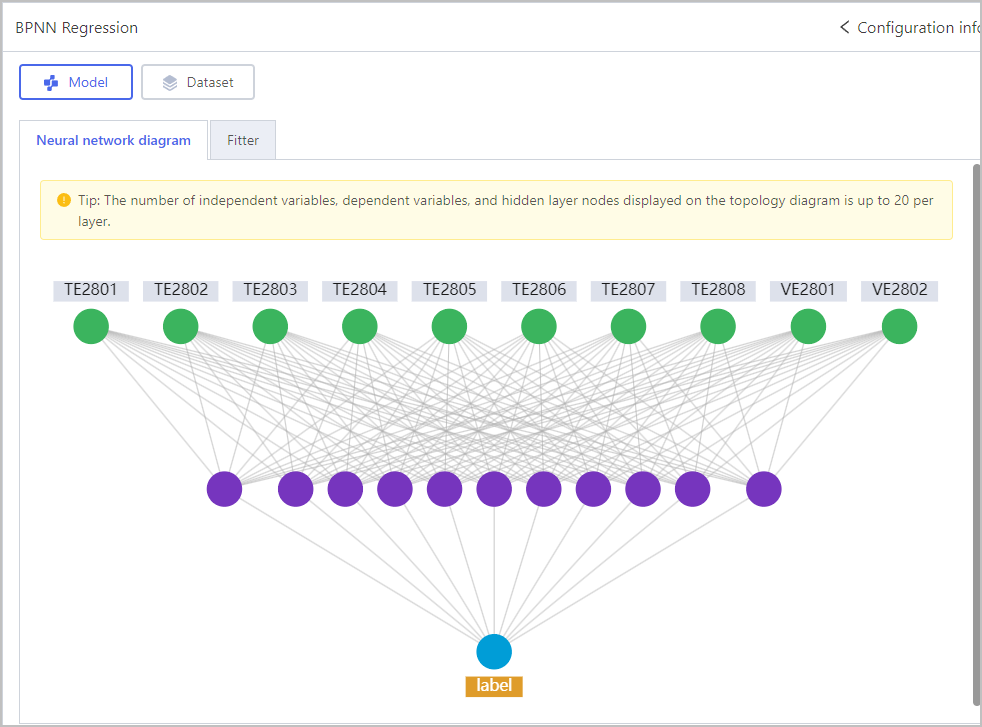
Regression-BPNN Regression
| Parameter | Description |
|---|---|
| Data normalization | To ensure that the input features are within a similar range and have comparable scales. |
| Hidden neuron | Determines the complexity and representational capacity of the network. |
| Weight decay | Prevent overfitting and improve generalization performance by adding a regularization term to the loss function during training, which penalizes large weight values. |
| Maximum number of iterations | The maximum number of training iterations or epochs that the algorithm will go through during the training process. |
| Prediction interval control | Manage the uncertainty or confidence associated with the predictions made by the model. |
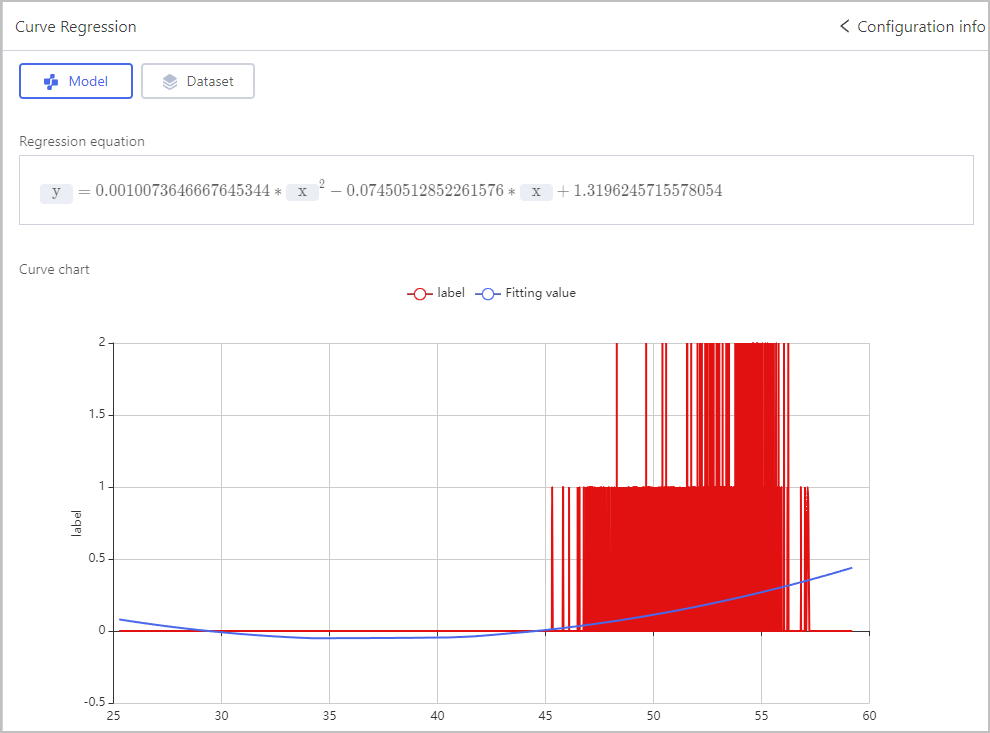
Regression-Curve Regression
Select one independent variable and one dependent variable in Set Role, and then set the order.
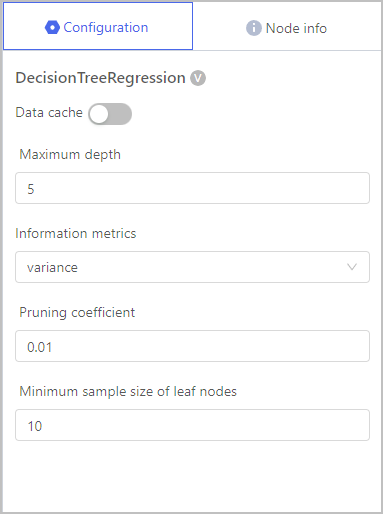
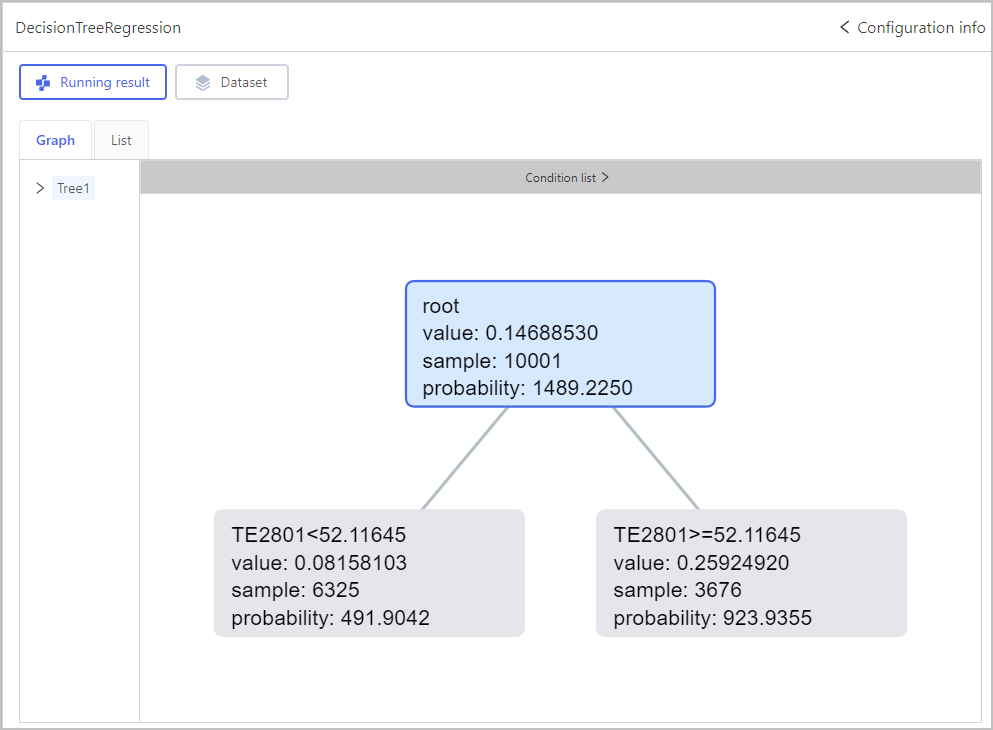
Regression-Decision Tree Regression
| Parameter | Description |
|---|---|
| Maximum depth | The maximum number of levels or node depths allowed in the decision tree model. |
| Information metrics | Only supports variance, meaning the squared difference between real value and predicted value. The smaller the calculated value, the better the model is fitted. |
| Pruning coefficient | Reduces the complexicy of the decision tree. The larger the value, the simpler the tree gets. caution The value should be set based on data set features and actual requirements. Underfitting or overfitting might happen due to unreasonable coefficient setting. |
| Minimum sample size of leaf nodes | Specifies the minimum number of samples required to consider further splitting a node and form a leaf node. |
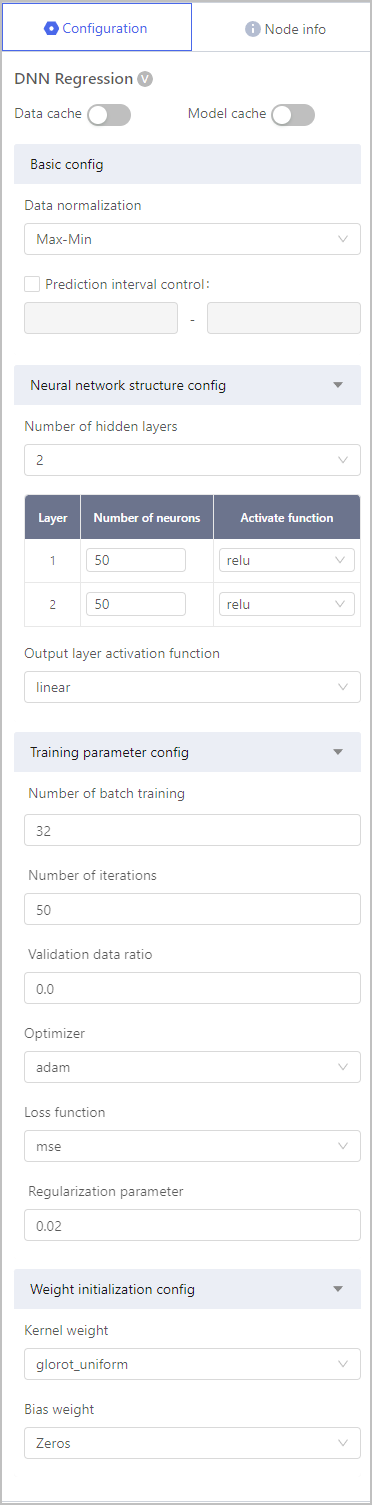
Regression-DNN Regression
| Parameter | Description |
|---|---|
| Data normalization | Scales the feature values of input data to a suitable range, making the training process of the neural network more stable and efficient. |
| Prediction interval control | Estimates the confidence intervals or variance ranges of the predicted values, providing more comprehensive information about the prediction results. |
| Number of hidden layers | Layers between the input layer and the output layer, where the actual learning and feature extraction occur. |
| Output layer activation function | The linear activation function simply outputs the weighted sum of the input without applying any non-linear transformation. |
| Number of batch training | The number of samples used in each batch during the training of a DNN regression model. |
| Number of iterations | The number of times the entire training dataset is processed by the neural network during the training process. |
| Validation data ratio | Represents the fraction of the total dataset that is set aside for validation during the model training process. |
| Optimizer | Determines how the model's parameters (weights and biases) are updated during the training process to minimize the loss function and improve the model's performance. |
| Loss function | Measures the discrepancy between the predicted output and the actual target values. |
| Regularization parameter | Helps prevent overfitting by adding a penalty term to the loss function, discouraging the model from becoming too complex and relying too much on the training data. |
| Kernel weight | The weights represent the strength of the connections between neurons in different layers. |
| Bias weight | Used to introduce an offset or bias to the output of the neuron. |

Regression-Linear Regression
| Parameter | Description |
|---|---|
| Regularization parameter | Prevents overfitting and improve the generalization ability of the model. It adds a regularization term to the loss function during training, which penalizes large coefficient values. The regularization parameter controls the strength of this penalty. |
| Penalty function type |
|

Regression-LSTM Regression
| Parameter | Description |
|---|---|
| Data normalization | Scales the feature values of input data to a suitable range, making the training process of the neural network more stable and efficient. |
| Prediction interval control | Estimates the confidence intervals or variance ranges of the predicted values, providing more comprehensive information about the prediction results. |
| Time step | The number of past observations or data points that are considered as input to the LSTM network when making a prediction for the next time step. |
| Number of LSTM layers | The depth of the LSTM architecture used in the model. When the dataset is small and noisy, it is better to set a smaller number. |
| Output layer activation function | The linear activation function simply outputs the weighted sum of the input without applying any non-linear transformation. |
| Number of batch training | The number of samples used in each batch during the training of a DNN regression model. |
| Number of iterations | The number of times the entire training dataset is processed by the neural network during the training process. |
| Validation data ratio | Represents the fraction of the total dataset that is set aside for validation during the model training process. |
| Optimizer | Determines how the model's parameters (weights and biases) are updated during the training process to minimize the loss function and improve the model's performance. |
| Loss function | Measures the discrepancy between the predicted output and the actual target values. |
| Regularization parameter | Helps prevent overfitting by adding a penalty term to the loss function, discouraging the model from becoming too complex and relying too much on the training data. |
| Kernel weight | The weights represent the strength of the connections between neurons in different layers. |
| Recurrent weight | The set of weights that control the recurrent connections within the LSTM cells. |
| Bias weight | Used to introduce an offset or bias to the output of the neuron. |

Regression-Nolinear SVM Regression
| Parameter | Description |
|---|---|
| Kernal function type | Maps the input data into a higher-dimensional space, where it becomes more suitable for linear regression. |
| Kernal function coefficient | Controls the shape and flexibility of the kernel function. |
| Penalty factor C | Controls the trade-off between maximizing the margin and minimizing the training error. |
| Error accuracy | The accuracy of the regression model in making predictions on the test or validation data. |
| Maximum number of iterations | Specifies the maximum number of times the optimization algorithm will update the model's parameters while trying to minimize the cost function or loss. |
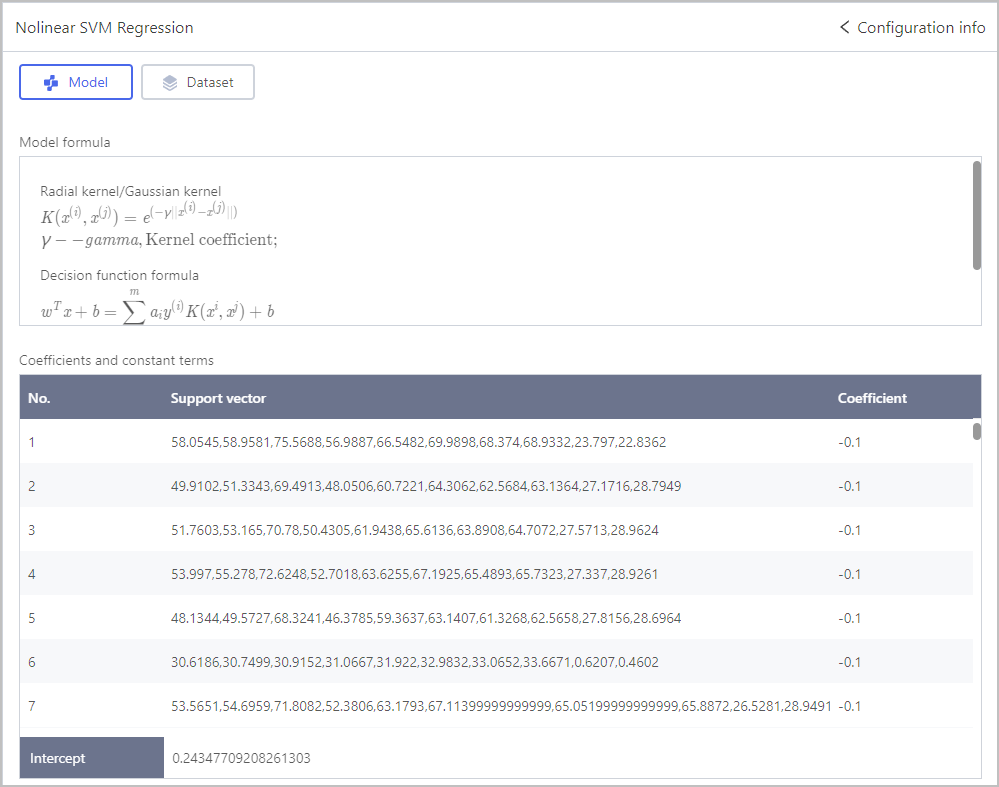
Regression-Random Forest Regression
| Parameter | Description |
|---|---|
| Number of trees | The number of decision trees that are built during the training process. |
| Maximum depth | The maximum number of levels or node depths allowed in the decision tree model. |
| Info metrics |
|
| Maximum feature | The maximum number of features considered during the construction of each decision tree in the ensemble. |
| Minimum sample size of leaf nodes | Specifies the minimum number of samples required to consider further splitting a node and form a leaf node. |
| Cost-complexity pruning | Ensures that each decision tree in the Random Forest is already relatively simple and less prone to overfitting. |
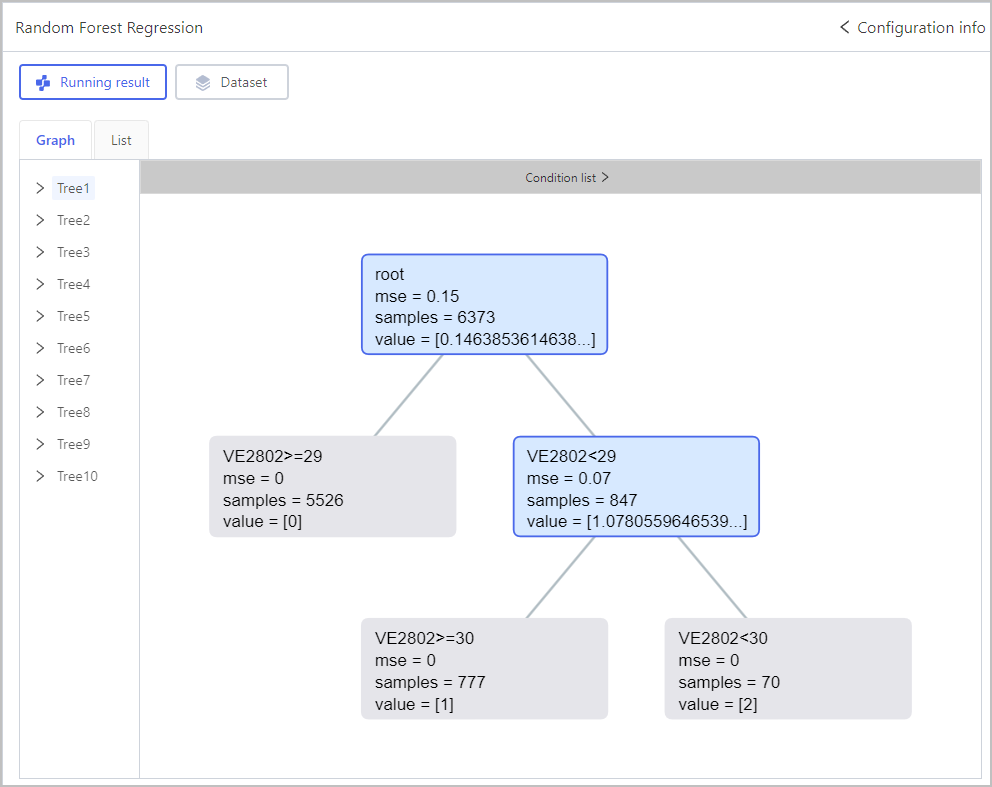
Regression-RNN Regression
| Parameter | Description |
|---|---|
| Data normalization | Scales the feature values of input data to a suitable range, making the training process of the neural network more stable and efficient. |
| Prediction interval control | Estimates the confidence intervals or variance ranges of the predicted values, providing more comprehensive information about the prediction results. |
| Time step | The number of past observations or data points that are considered as input to the LSTM network when making a prediction for the next time step. |
| Number of LSTM layers | The depth of the LSTM architecture used in the model. When the dataset is small and noisy, it is better to set a smaller number. |
| Output layer activation function | The linear activation function simply outputs the weighted sum of the input without applying any non-linear transformation. |
| Number of batch training | The number of samples used in each batch during the training of a DNN regression model. |
| Number of iterations | The number of times the entire training dataset is processed by the neural network during the training process. |
| Validation data ratio | Represents the fraction of the total dataset that is set aside for validation during the model training process. |
| Optimizer | Determines how the model's parameters (weights and biases) are updated during the training process to minimize the loss function and improve the model's performance. |
| Loss function | Measures the discrepancy between the predicted output and the actual target values. |
| Regularization parameter | Helps prevent overfitting by adding a penalty term to the loss function, discouraging the model from becoming too complex and relying too much on the training data. |
| Kernel weight | The weights represent the strength of the connections between neurons in different layers. |
| Recurrent weight | The set of weights that control the recurrent connections within the LSTM cells. |
| Bias weight | Used to introduce an offset or bias to the output of the neuron. |
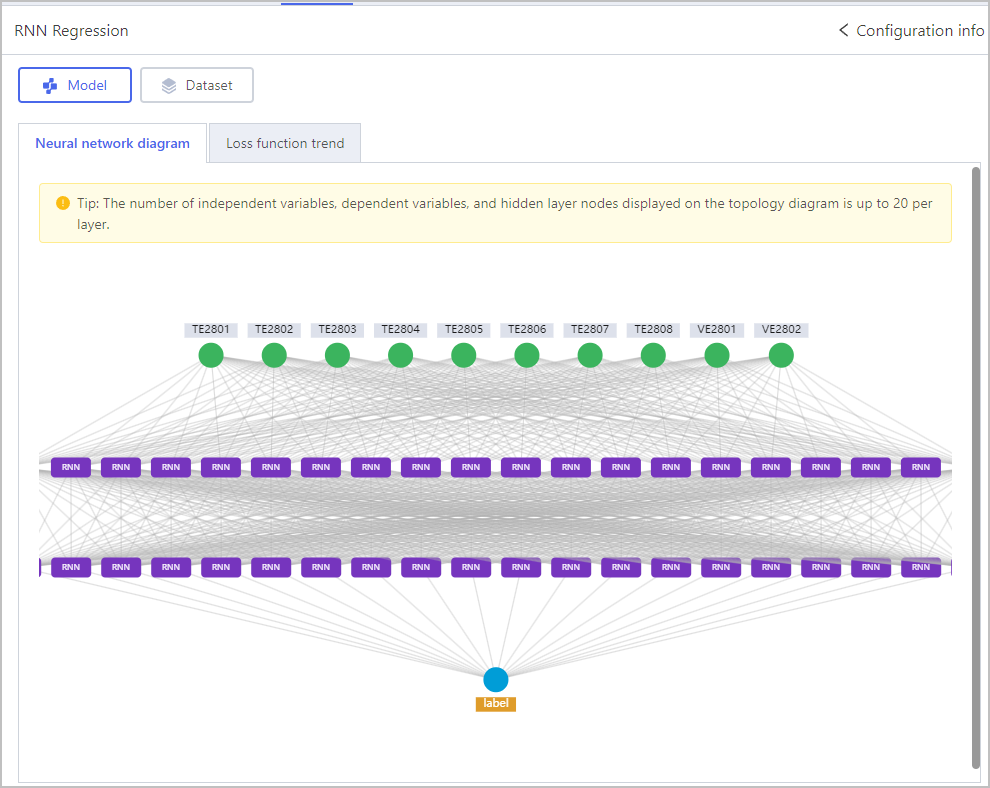
Regression-XGB Regression
| Parameter | Description |
|---|---|
| Weak estimator | A variant of decision trees that focuses on minimizing the gradients of the loss function during training. Each weak estimator is trained to correct the errors made by the previous estimators, gradually improving the model's predictions. |
| Objective function | The loss function to be minimized during the training process. It quantifies the discrepancy between the predicted values and the true target values, guiding the optimization of the XGBoost regression model. |
| Maximum depth | The maximum number of levels or node depths allowed in the decision tree model. |
| Learning rate | Controls the contribution of each weak learner to the overall ensemble model. |
| Minimum loss of leaf nodes | Control the minimum amount of improvement required to split a leaf node further. It determines whether a further split at a leaf node will be considered based on the reduction in the loss function achieved by the split. |
| Leaf node weight | The values assigned to the leaf nodes of each decision tree in the ensemble. |
| Maximum iteration step | Specifies the maximum depth or number of levels allowed for each decision tree. |
| L1/2 regular parameters | Control the strength of L1 and L2 regularization techniques used in the model. Which prevents overfitting and improve the generalization ability of the XGBoost regression model by adding penalty terms to the loss function. |
| Number of iterations | Determines the maximum number of decision trees to be built during the training process. |
Classification-BPNN Classification
| Parameter | Description |
|---|---|
| Hidden neuron | Represents the number of neurons in the hidden layer of the neural network, which is a crucial component that allows the network to learn complex representations and patterns from the input data. |
| Weight decay | Prevents overfitting and improve the generalization ability of the model. |
| Maximum number of iterations | Sets an upper limit on the number of times the training algorithm will update the model's weights. |
Classification-CART Decision Tree Classification
| Parameter | Description |
|---|---|
| Maximum depth | The maximum allowed depth of a tree in the algorithm. |
| Information metrics | Evaluates the quality of a split at each node. |
| Pruning coefficient | Used in the process of cost-complexity pruning, which is a technique to prevent overfitting and improve the generalization ability of the decision tree. |
| Maximum sample size of leaf nodes | Specifies the minimum number of samples required to create a leaf node during the tree-building process. |
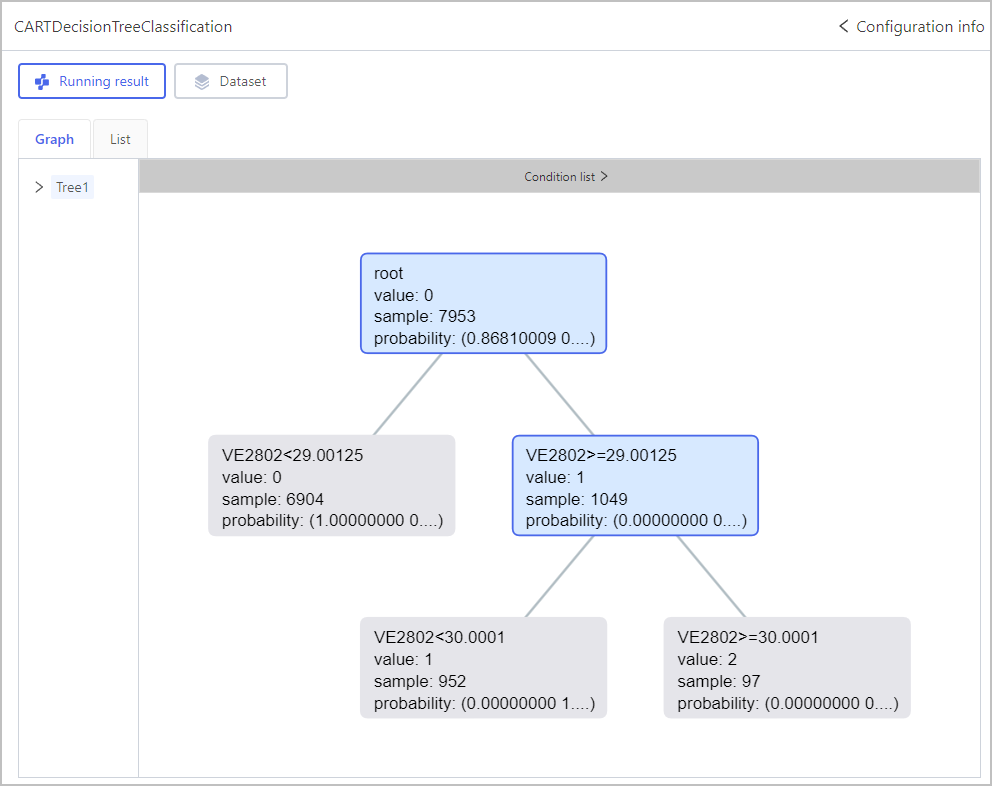
Classification-ID3 Decision Tree
| Parameter | Description |
|---|---|
| Maximum depth | The maximum allowed depth of a tree in the algorithm. |
| Information metrics | Evaluates the quality of a split at each node. |
| Pruning coefficient | Used in the process of cost-complexity pruning, which is a technique to prevent overfitting and improve the generalization ability of the decision tree. |
| Maximum sample size of leaf nodes | Specifies the minimum number of samples required to create a leaf node during the tree-building process. |
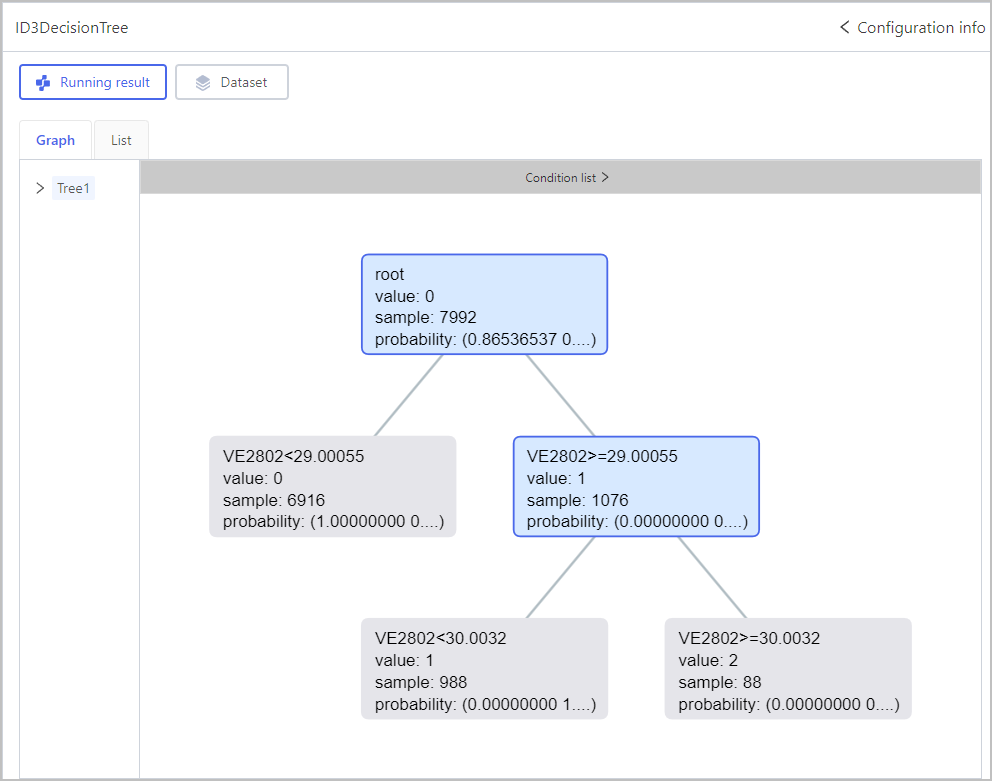
Classification-KNN Classification
| Parameter | Description |
|---|---|
| Data normalization | A preprocessing step to ensure that all features have a similar scale and range. |
| Number of nearest neighbors | The value of K, which represents the number of data points or neighbors to consider when making predictions for a new data point. |
| Measure distance | Calculate the distance between data points in the feature space. |
Classification-Logical Regression
| Parameter | Description |
|---|---|
| Regularization parameter | Used to control the amount of regularization applied to the logistic regression model. |
| Penalty function type |
|
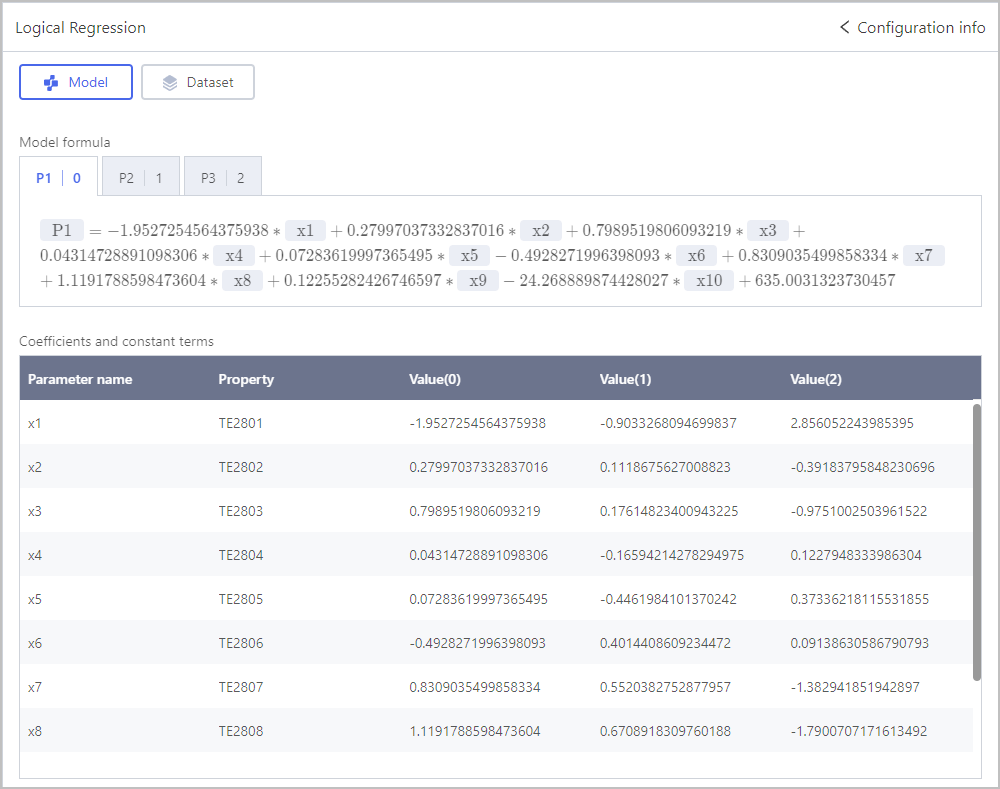
Classification-Random Forest Classifier
| Parameter | Description |
|---|---|
| Number of trees | The number of decision trees that are built during the training process. |
| Maximum depth | The maximum number of levels or node depths allowed in the decision tree model. |
| Info metrics |
|
| Maximum feature | The maximum number of features considered during the construction of each decision tree in the ensemble. |
| Minimum sample size of leaf nodes | Specifies the minimum number of samples required to consider further splitting a node and form a leaf node. |
| Cost-complexity pruning | Ensures that each decision tree in the Random Forest is already relatively simple and less prone to overfitting. |
Classification-XGBoost Classification
| Parameter | Description |
|---|---|
| Weak estimator | A variant of decision trees that focuses on minimizing the gradients of the loss function during training. Each weak estimator is trained to correct the errors made by the previous estimators, gradually improving the model's predictions. |
| Objective function | The loss function to be minimized during the training process. It quantifies the discrepancy between the predicted values and the true target values, guiding the optimization of the XGBoost regression model. |
| Maximum depth | The maximum number of levels or node depths allowed in the decision tree model. |
| Learning rate | Controls the contribution of each weak learner to the overall ensemble model. |
| Minimum loss of leaf nodes | Control the minimum amount of improvement required to split a leaf node further. It determines whether a further split at a leaf node will be considered based on the reduction in the loss function achieved by the split. |
| Leaf node weight | The values assigned to the leaf nodes of each decision tree in the ensemble. |
| Maximum iteration step | Specifies the maximum depth or number of levels allowed for each decision tree. |
| L1/2 regular parameters | Control the strength of L1 and L2 regularization techniques used in the model. Which prevents overfitting and improve the generalization ability of the XGBoost regression model by adding penalty terms to the loss function. |
| Number of iterations | Determines the maximum number of decision trees to be built during the training process. |
Cluster-EM
| Parameter | Description |
|---|---|
| Number of clusters | Represents the number of clusters that the algorithm will attempt to identify in the data. |
| Maximum number of iterations | The maximum allowed number of iterations that the algorithm can run before it stops. |
Cluster-KMeans
| Parameter | Description |
|---|---|
| Data standard | The process of scaling the features or variables in the dataset to have a mean of 0 and a standard deviation of 1. |
| Number of clusters | Determines the number of clusters the algorithm will attempt to identify in the data. |
| Maximum number of iterations | The maximum allowed number of iterations that the algorithm can run before it stops. |
| Distance metric type | The Euclidean distance is a measure of the straight-line distance between two data points in a multidimensional space. |
Optimization-Genetic Algorithm
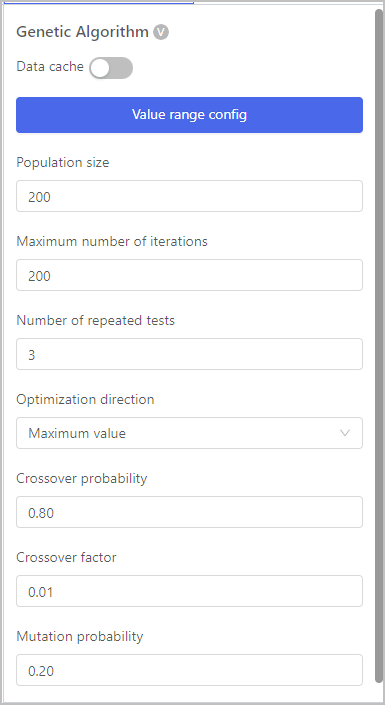
| Parameter | Description |
|---|---|
| Value range config | Set the value range of the independent variable. |
| Population size | Represents the number of potential solutions that are evolved and evaluated in each generation. |
| Maximum number of iterations | The maximum allowed number of generations that the algorithm can run before it terminates. |
| Number of repeated tests | How many times the algorithm is executed with different random initializations or settings. |
| Optimization direction | Whether the algorithm is being used for maximization or minimization of a specific objective function. |
| Crossover probability | The probability of applying crossover to create new offspring during the reproduction step of the algorithm. |
| Crossover factor | The proportion of the population that will undergo crossover to produce offspring in the next generation. |
| Mutation probability | The probability of applying mutation to an individual's genetic information during the reproduction step of the algorithm. |
Custom
Python Script
Dependencies can be imported through Env Resources > Packages
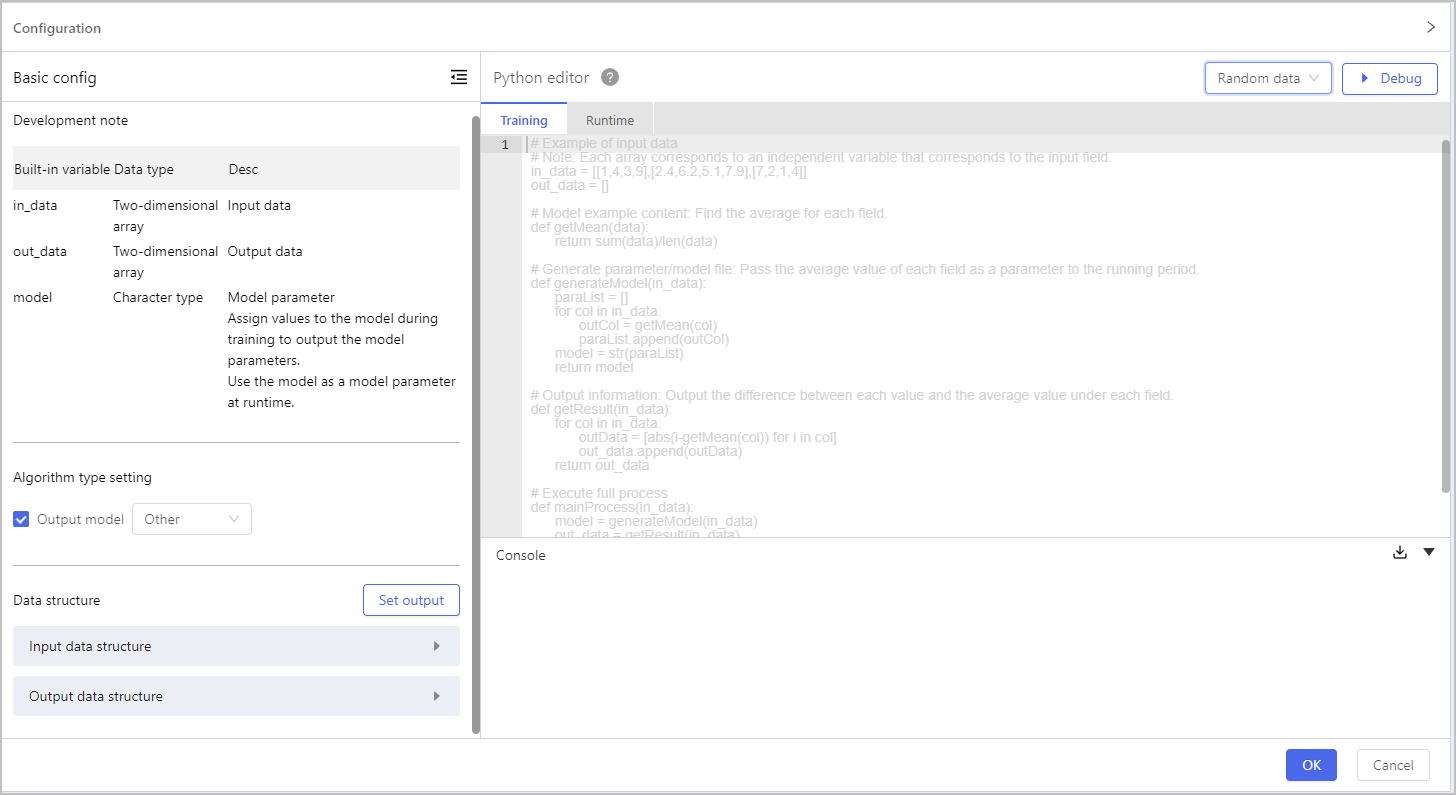
| Parameter | Description |
|---|---|
| Development note | Displays input/output data and model information which will be used in your script. |
| Algorithm type setting | Select the output algorithm type from Regression, Classification, Cluster and Other. |
| Data structure | Click Set output, and then you can either take refrence from the input fields (Reference input) or create new fields (New) to be the output fields. |
| Python editor | Write your script of both Training and Runtime, and then click Debug to make sure it runs correctly before applying to the model. |
Model Assessment
| Type | Description |
|---|---|
| Classification Eval | Evaluate classification model precision based on the applied model calculation. |
| Cluster Eval | Evaluate cluster model precision based on the applied model calculation. |
| Model Apply | Use validation data to test the applied model. |
| Regression Eval | Evaluate regression model precision based on the applied model calculation and set grading standard. |